Objekterkennung mit dem Pascal-basierten neuronalen Netzwerk-API
CAI NEURAL API ist ein Pascal-basiertes neuronales Netzwerk-API, das für AVX-, AVX2 und AVX512-Befehlssätze sowie OpenCL-fähige Geräte wie AMD, Intel und NVIDIA für GPU-Funktionen optimiert ist. Das API wurde unter Windows und Linux getestet. Im Februar 2020 erhielten wir noch Delphi-Unterstützung für OpenCL und Threads. Dieses Projekt und das API sind ein Teilprojekt eines größeren und älteren Projekts namens CAI und seiner Schwester, das Keras/TensorFlow-basierte K-CAI NEURAL-API.
Die Bilderkennung hat in vielen Bereichen der Bildverarbeitung einen raschen revolutionären Wandel erlebt. (Abb. 1). Sein Anteil an der Kombination von Objektklassifizierung und Objekterkennung macht es zu einem der herausforderndsten Themen im Bereich des maschinellen Lernens.

Abb. 1: Objekterkennung mit Machine Learning
Am Anfang steht die CAI-Bibliothek mit Modulen. Neural-API ist eine Pascal-Bibliothek, mit der man Systeme mit eigenständigen Deep-Learning- und Computer-Vision-Funktionen mit wenigen Zeilen kompakten Code erstellen und ausführen kann. Sie benötigen eine Lazarus- oder Delphi-Entwicklungsumgebung. Wenn Sie ein OpenCL-fähiges Gerät haben, benötigen Sie auch dessen OpenCL-GPU-Treiber. Um CAI zuerst zu verwenden, müssen jedoch einige Abhängigkeiten installiert werden, nämlich:
- dglOpenGL
- OpenCV as CL or OpenCL
- CL_Platform
- Neuralvolume, neuralnetwork, neuralab, etc.
Nach der Installation von CAI ist eine einfache Dokumentation in einer Readme-Datei vorhanden. In Bezug auf Delphi werden einige Units mit Delphi kompiliert und Sie können mit Delphi – in meinem Fall mit der Community Edition 10.3 – neuronale Netze erstellen und ausführen (siehe Abb. 1 unten). Für Keras und Tensorflow ist auch ein git clone vorhanden.

Eine andere faszinierende Möglichkeit besteht darin, das gesamte System als Runtime-Virtualisierung mit Hilfe eines Jupyter-Notebooks, das unter Ubuntu in der Cloud ausgeführt wird, auf Google Colab oder Colab.research-Container auszuführen. Eingeschlossen ist der Build von Free Pascal mit Lazarus, wie man unter folgendem Link nachvollziehen kann: https://github.com/maxkleiner/maXbox/blob/master/EKON24_SimpleImageClassificationCPU.ipynb
!apt-get install fpc fpc-source lazarus git subversion
Jupyter ist ein Spin-off-Projekt von IPython, das darauf abzielt, interaktives Computing in allen Programmiersprachen zu standardisieren. Der Kernel bietet eine interaktive Umgebung, in der Benutzercode im Server ausgeführt wird, der mit einem Frontend-Through-Socket verbunden ist. Das Framework wie auch CAI ist Open Source. Es lässt sich unter den Bedingungen der GNU General Public License und der Free Software Foundation weitergeben und/oder ändern.
Als nächstes lade ich die CIFAR-Modelldatei (162 MB) herunter, die fünf Volumes als Verzeichnisse für das Klassifizierungsmodell enthält, das für das Objekttraining und die Objekterkennung verwendet wird.
Der CIFAR-10-Datensatz besteht aus 60000 32×32-Farbbildern in 10 Klassen mit 6000 Bildern pro Klasse. Es gibt 50000 Trainingsbilder und 10000 Testbilder. Der Datensatz ist in fünf Trainingsstapel (data_batch_1.bin – _5.bin) und einen Teststapel mit jeweils 10000 Bildern unterteilt. Der Teststapel enthält genau 1000 zufällig ausgewählte Bilder aus jeder Klasse. Die Trainingsstapel enthalten die verbleibenden Bilder in zufälliger Reihenfolge, aber einige Trainingsstapel enthalten möglicherweise mehr Bilder aus einer Klasse als aus einer anderen. Dazwischen enthalten die Trainingsstapel genau 5000 Bilder aus jeder Klasse.
Die Klassen schließen sich vollständig gegenseitig aus. Es gibt keine Überlappung zwischen Autos und Lastwagen oder Katze und Hund, man sagt auch die Klassen sind disjunkt. Die Klassen sind:
classes=(‘plane’,’car’,’bird’,’cat’,
‘deer’,’dog’,’frog’,’horse’,’ship’,’truck’)
Diese Ergebnisse resultieren aus einem Convolution-Netzwerk. Kurz gesagt, es sind 18% als Testfehler zu erkennen. Ein einzelnes Bild hat bewusst eine niedrige Auflösung zum Trainieren der Merkmalsträger (Features) (Abb. 2).
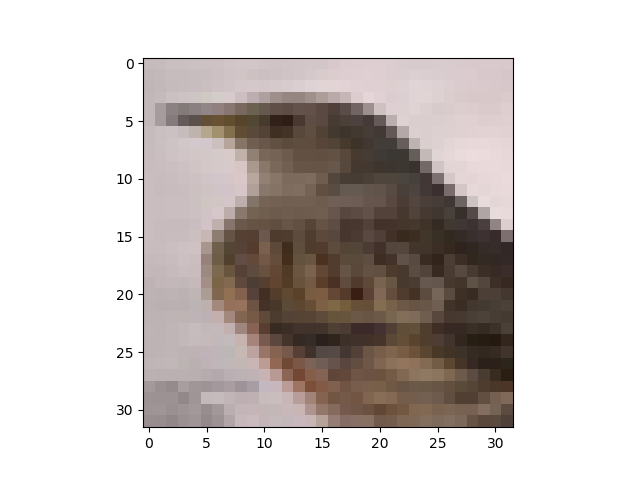
Abb. 2: Einzelnes Bild zum Trainieren der Features
Nach dem Einrichten der Units und dem Beziehen der Bilddaten öffne ich den Code-Editor meiner Wahl (in meinem Fall maXbox, Jupyter Notebook und Delphi Community Edition) und lade die Dateibeispiele SimpleImageClassifier.lpi oder in Delphi die Datei SimpleImageClassifier_CPU_Cifar.pas (Abb. 3).
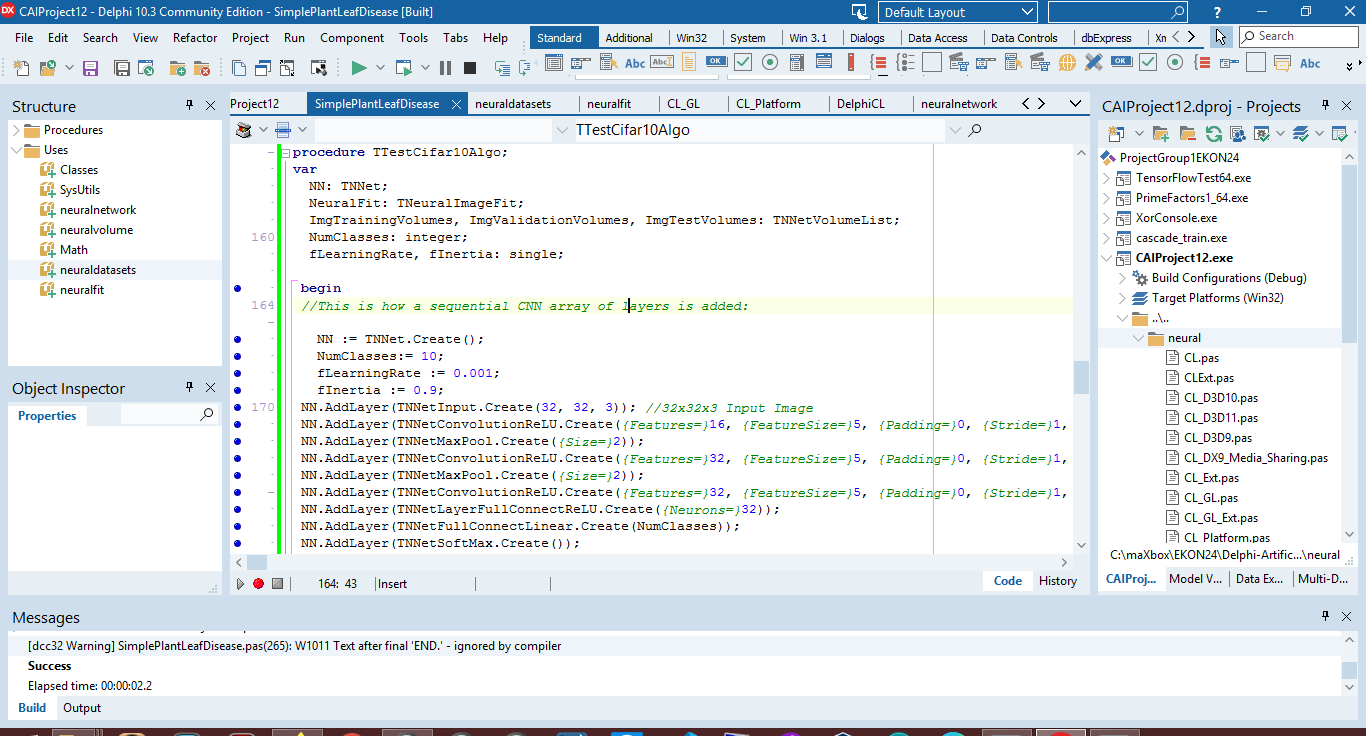
Abb. 3: Dateibeispiele im Editor
Dieses Beispiel enthält interessante Aspekte: Der Quellcode ist klein und die Ebenen werden als Layer nacheinander hinzugefügt. Anschließend lassen sich die Trainingshyperparameter definieren, bevor die Fit-Methode aufgerufen wird. Sie benötigen fit(), um das Modell zu trainieren! In Zeile 155 beginne ich mit der Testklasse aus der CAI-Bibliothek und erstelle auch die ersten neuronalen Schichten als Modelldefinition:
procedure TTestCifar10Algo;
var
NN: TNNet;
NeuralFit: TNeuralImageFit;
ImgTrainingVolumes, ImgValidationVolumes, ImgTestVolumes: TNNetVolumeList;
NumClasses: integer;
fLearningRate, fInertia: single;
begin
//This is how a sequential CNN array of layers is added:
NN:= TNNet.Create();
NumClasses:= 10;
fLearningRate:= 0.001;
fInertia:= 0.9;
NN.AddLayer(TNNetInput.Create(32, 32, 3)); //32x32x3 Input Image
NN.AddLayer(TNNetConvolutionReLU.Create({Features=}16, {FeatureSize=}5, {Padding=}0, {Stride=}1, {SuppressBias=}0));
NN.AddLayer(TNNetMaxPool.Create({Size=}2));
NN.AddLayer(TNNetConvolutionReLU.Create(32, 5, 0, {Stride=}1, 0));
NN.AddLayer(TNNetMaxPool.Create({Size=}2));
NN.AddLayer(TNNetConvolutionReLU.Create(32, 5, 0, {Stride=}1, 0));
NN.AddLayer(TNNetLayerFullConnectReLU.Create({Neurons=}32));
NN.AddLayer(TNNetFullConnectLinear.Create(NumClasses));
NN.AddLayer(TNNetSoftMax.Create());
writeln(NN.SaveDataToString);
//readln;
Dann lade ich die Datensets für das Training. Es gibt einen Trick, den Sie mit diesem API oder einem anderen API ausführen können, wenn Sie mit der Bildklassifizierung arbeiten: Sie können die Größe des Eingabebilds erhöhen. Gemäß dem folgenden Beispiel (Trainieren, Testen und Validieren) können Sie durch Erhöhen der CIFAR-10-Eingabebildgröße von 32 x 32 auf 48 x 48 die Klassifizierungsgenauigkeit um bis zu 2% steigern.
CreateCifar10Volumes(ImgTrainingVolumes, ImgValidationVolumes, ImgTestVolumes);
WriteLn
(
‘Training Images:’, ImgTrainingVolumes.Count,
‘ Validation Images:’, ImgValidationVolumes.Count,
‘ Test Images:’, ImgTestVolumes.Count
); //*)
WriteLn(‘Neural Network will minimize error with:’);
WriteLn(‘ Layers: ‘, NN.CountLayers());
WriteLn(‘ Neurons: ‘, NN.CountNeurons());
WriteLn(‘ Weights: ‘, NN.CountWeights());
writeln(‘Start Convolution Net…’);
readln;
Als Ausgabe auf der Shell sieht man, dass das Neuronale Netzwerk Fehler mit Hilfe einer Loss-Funktion und der Lernrate minimiert:
Layers: 9
Neurons: 122
Weights: 40944
Start Convolution Net…
NeuralFit:= TNeuralImageFit.Create;
//readln;
NeuralFit.FileNameBase:= ‘EKONSimpleImageClassifier2’;
NeuralFit.InitialLearningRate:= fLearningRate;
NeuralFit.Inertia:= fInertia;
NeuralFit.LearningRateDecay:= 0.005;
NeuralFit.StaircaseEpochs:= 17;
// NeuralFit.Inertia := 0.9;
NeuralFit.L2Decay:= 0.00001;
// best fit: batch 128 epochs 100
// just for test and evaluate the process – epochs = 1, otherwise 10 or 100!
NeuralFit.Fit(NN, ImgTrainingVolumes, ImgValidationVolumes, ImgTestVolumes, NumClasses, {batchsize}128, {epochs}1);
writeln(‘End Convolution Net…’);
readln;
NeuralFit.Free;
NN.Free;
ImgTestVolumes.Free;
ImgValidationVolumes.Free;
ImgTrainingVolumes.Free;
end;
Die Lernrate in NeuralFit.InitialLearningRate:= fLearningRate; ist ein wichtiger Hyperparameter, der steuert, wie stark der Algorithmus die Gewichte und Verbindungen im Netzwerk entsprechend dem Gradienten anpassen soll.
Wie in einem Gradienten Histogramm (HOG) handelt es sich im Grunde genommen um einen Merkmalsdeskriptor, der zum Erkennen von Objekten in der Bildverarbeitung und anderen Computer-Vision-Techniken verwendet wird. Das erzeugte Histogramm der Deskriptoren umfasst das Auftreten von Gradientenorientierung in lokalisierten Teilen eines Bildes, wie z.B. Erfassungsfenster, Region of Interest (ROI), Frames und andere. Der Vorteil von HOG-ähnlichen Funktionen liegt in ihrer Einfachheit und dem leichteren Verständnis der darin enthaltenen und gefundenen Information.
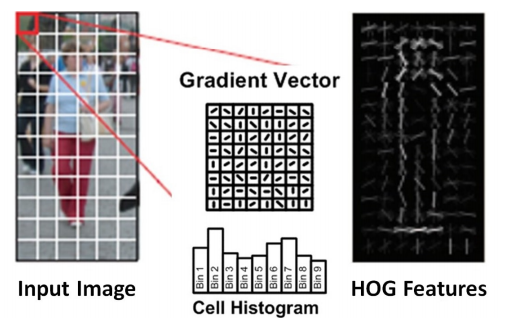
Abb. 4: HOG Features
Bleibe informiert
Für Newsletter anmeden
Im letzten Schritt sehen wir die Bilderkennung, die sich auf Menschen oder Personen spezialisiert hat. Überraschenderweise werden nach einem Bild (Die Nachtwache, Delft, Abb. 5) die Personen im Hintergrund eher erkannt als die reale Person im Vordergrund. Das hat mit dem Bildausschnitt im Sinne der Fokussierung des Rechtecks zu tun, da jeweils eine ganze Person trainiert wurde.
person : 11.248066276311874
person : 14.372693002223969
person : 19.247493147850037
person : 34.878602623939514
person : 77.2484838962555
image detector compute ends…
#loads model from path specified above using the setModelPath() class method.
detector.loadModel()

Abb. 5: Bilderkennung für Personen
Fazit
Wie lassen sich also die Validierungszeiten verkürzen? Mit einem vortrainierten Modell! Vorgefertigte Modelle sind eine wunderbare Hilfe für Entwickler und Entscheider, die einen Algorithmus erlernen oder ein vorhandenes Framework online oder offline ausprobieren möchten. Die Vorhersagen, die mit vorab trainierten Modellen getroffen wurden, wären jedoch nicht so effektiv, als wenn Sie das Modell mit Ihren eigenen Daten trainieren. Das ist der Kompromiss. Aus zeitlichen oder rechnerischen Gründen ist es nicht immer möglich, ein Modell von Grund auf neu zu erstellen (wie wir es getan haben), weshalb es vortrainierte Modelle wie das pretrained-yolov3.h5 und viele aus dem ImageNet gibt. Wer das beschriebene Beispiel nachvollziehen möchte, findet unter softwareschule.ch, sourceforge.net und sourceforge.net das Skript und die verwendeten Daten.



